

Part 2: AI Terms Explained - Vector Database,Embeddings ,RAG ,Fine-tuning , Attention ,Transformers ,RLHF, ,Tokenization, AI Agents and resources to learn more

If you missed Part 1? Catch up here
As I am writing about what I have learned and whats going on in the AI wild , I am using AI tools to explore the ideas. These tools help me brainstorm and act as my assistants to nudge me in the right direction.
When I was reviewing what I should be writing for next part, the logical step was going into level 2 of what we covered in part 1. As I was working through it, chatbots suggested to write about weights and biases , loss functions , hidden layers etc. This definitely needed better prompting.
Then I put myself in reader’s shoes and remembered what other popular terms that are mentioned on the social media, when talked about AI, that are not covered in my part 1. Then I suggested to focus on terms like Transformers , Vector databases, embeddings etc. It did give me some good terms along those lines to focus on. This is what I am going to cover today.
I am working on a chatbot project which involves vector database and embeddings which inspired me focus on some of these topics and hopefully we can cover that during next newsletter
If you’ve heard terms like Transformers, Fine-tuning, or Vector DBs flying around in meetings, on Twitter, or in random podcast episodes but never had time to Google them… this one's for you.
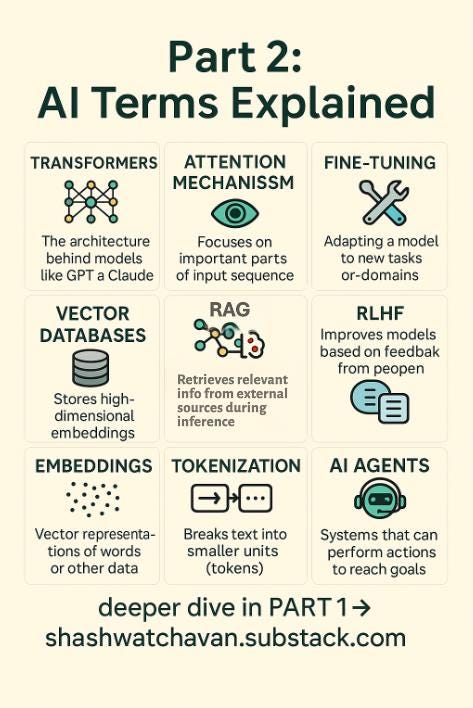
1.Transformers
These are the backbone of modern AI models like GPT, Claude, and Gemini. A great definition from Nvidia Blog
‘A transformer model is a neural network that learns context and thus meaning by tracking relationships in sequential data like the words in this sentence.‘
GPT is a Generative Pre-Trained Transformer. These transformers take a sequence of words and turn it into another sequence, understanding the context of each word. They use a concept called Attention, which means they pay closer attention to some words than others to better understand the meaning.
If you are a visual learner, you will love this video from 3Blue1Brown on Transformers.
2. 👀 Attention Mechanism
A key feature inside Transformers. As you read earlier, Transformers use attention to focus on certain words. But how and why?
Attention is a technique in neural network that allows model to focus on the most relevant parts of the input data when making predictions. This helps the model treat each element seperately rather than given weightage to each word equally. This makes model give us a more relevant response and this is what gave you those aha moments when you started using using ChatGPT and other models.
If you are feeling motivated to read the viral paper, check out the link to this white paper from #Google named “Attention is all you need” - Link
3. 🧠 Fine-Tuning
Training an already-trained model (like GPT-3) on your own data. You might have heard about base models. These are models which are trained on lots of data from public and private information and datasets.
Now what if you want to take these models and perform a task for your personal use case, for your company or particular domain. These models have general world understanding but they dont excel in particualr tasks.
You have provide a your data, train the data and model the tasks you want it to perform. This process is called Fine-tuning.
You may want to perform sentimental analysis or machine translation etc. Fine tuning will help you achieve those tasks.
This is also a form of transfer learning where knowledge gained from one task is applied to another related tasks.
4. 🧭 Reinforcement Learning from Human Feedback (RLHF)
This is a process where human is involved. Its a way to fine-tune the models. Its a machine learning technique which uses human feedback to train a reward model which is then used to optimize the model you are training for your final task(s).
Here, humans provide the feedback on the quality and appropriateness of the model output. This feedback is then used to reward or punish the model based on the positive or negative feedback.
RLHF aims to align the models behavior with human values, preferences intentions etc. which will provide better response eventually.
This is most probably how ChatGPT got less weird and more helpful and Netflix is getting better at recommendations( by training and improving the model with the help of humans in the loop)
5. 🧱 Vector Database (e.g., Pinecone, Weaviate, MongoDB)
To understand vector databases, lets understand the vectors. Vectors are ordered list of numbers that captures the features and attributes of data.
Vectors can have hundreds and thousands of dimensions allowing for the representation of complex data.
So the Vector database stores a data as a high dimensional vectors, which allows efficient similarity search and retrieval.
Now you may ask, what is similarity search?
To put it simply, its the process of finding items in a dataset that are most similar to given query item based on a defined similarity search.
In Vector databases like Weaviate, Pinecone and even MongoDB, the data is indexed using various data structures. These data structures include, trees, graphs, hash-based indexes etc.

One of the most powerful use cases is RAG.
They are Used in RAG systems and AI memory.It’s how tools like Notion AI and ChatGPT “remember” your stuff. They are also used for recommendation systems, fraud detection and NLP(Natural Language Processing)
6. 🪄 Embeddings
Its a way to convert words into high-dimensional vectors. Its a representation of data such as text, , audio in a high dimensional vector space, where each dimension captures specific feature or attribute of the data.
Here the data is transformed into numerical vectors, allowing the mathematical operations to be performed on it. It also helps with semantic meaning which is derived from position and orientation of vectors in the embedding space to capture the meaning and relationship between the two data points.

Think of it as the math that lets AI understand semantic similarity.
(“Big” and “Large” look close in vector space.)
7. Tokenization
AI doesn’t see “words”—it sees tokens. Tokenization is the process of breaking down text into smaller units( in this case tokens) such as words, or characters which are then used as input for AI models.
Tokenization is crucial for text process where its helpful for AI models to understand and process text. It also helps create a vocabulary of unique tokens from corpus of text, which is then used to build the language models.
Tokens are often converted into embeddings which makes it easier for AI models to process.
 - Ayar Labs")
8. 🧠💾 RAG (Retrieval-Augmented Generation)
RAG is a framework for enhancing the LLM(Large Language Models) output with the help of external knowledge. It is used for information retrieval by LLM to get the latest and up to date data.
Ex. You are interacting with Chatbot to get the information about latest ChatGPT model. Most of the LLMs have knowledge cut off date Ex. Jan 2025. If you ask the LLM a question for latest model, it will give the information based on the latest information used as of Jan 2025.
Now with RAG, ChatGPT can use web search or any other tool at its disposal to get the latest information it has. This need not be a web search only. Typically, its a knowledge source ,knowledge base that was provided in the form of database, doc repository or anything that can have latest or relevant information, which needs to be retrieved based on the user query.
Think:
ChatGPT + Google + your own files.
? | DataCamp")
9. 🤖 AI Agents
I am sure I can come up with a decent definition of the AI agents but I would like to share a great definition shared by Anthropic team in very informative and popular article- Building Effective Agents - Link
Below is the excerpt from Anthropic blog post.
What are agents?
"Agent" can be defined in several ways. Some customers define agents as fully autonomous systems that operate independently over extended periods, using various tools to accomplish complex tasks. Others use the term to describe more prescriptive implementations that follow predefined workflows. At Anthropic, we categorize all these variations as agentic systems, but draw an important architectural distinction between workflows and agents:
Workflows are systems where LLMs and tools are orchestrated through predefined code paths.
Agents, on the other hand, are systems where LLMs dynamically direct their own processes and tool usage, maintaining control over how they accomplish tasks.
The key thing about AI agents compared to workflows or automation is that they are autonomous. They can operate idenpendtly without human in the loop or human intervention.
Bonus Buzzwords to Keep an Eye On:
Zero-shot / Few-shot: AI learning from no or few examples
Chain-of-thought prompting: Helping AI think step-by-step
Multi-modal: Models that handle text, image, and more
Alignment: Making sure AI follows human values
Inference time: How long AI takes to respond
You now know what powers modern AI—and you didn’t need a PhD to get here.
✅ Vector DBs
✅ RAG
✅ Fine-tuning
✅ Embeddings
✅ Attention
✅ Transformers
✅ RLHF
✅ LoRA
✅ Tokenization
✅ AI Agents
If this helped you feel smarter about AI in 5 minutes, do me a favor:
👉 Forward this to one friend in tech who’s trying to up-skill
💬 Leave a comment: What term should we unpack next in Part 3?
🔁 Repost on LinkedIn to help others level up
Thank you